O Dashboard do SkyWatch oferece uma visão geral do status da rede monitorada. Ele consolida os principais indicadores de desempenho, além de alertar sobre falhas ativas, permitindo uma resposta rápida a problemas de conectividade.
O que você encontra no Dashboard #
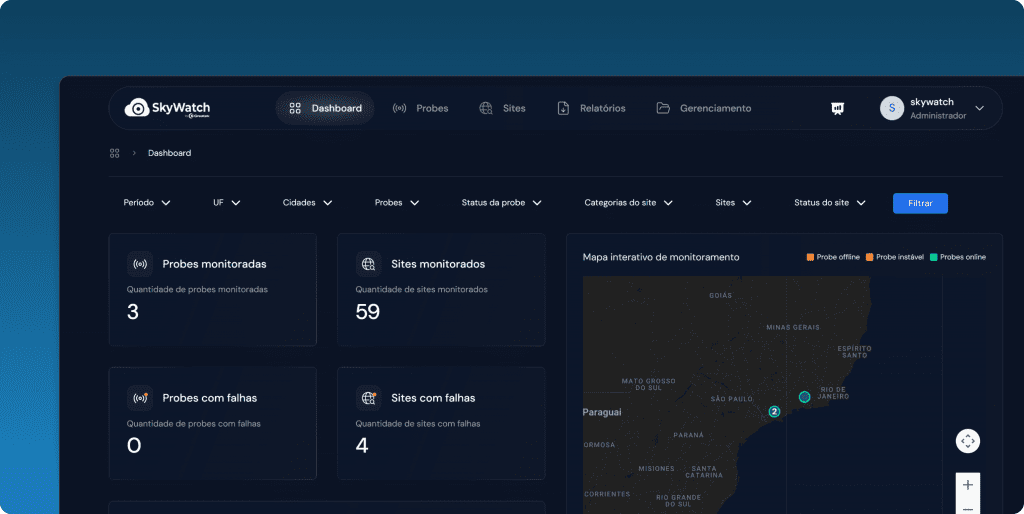
Indicadores principais #
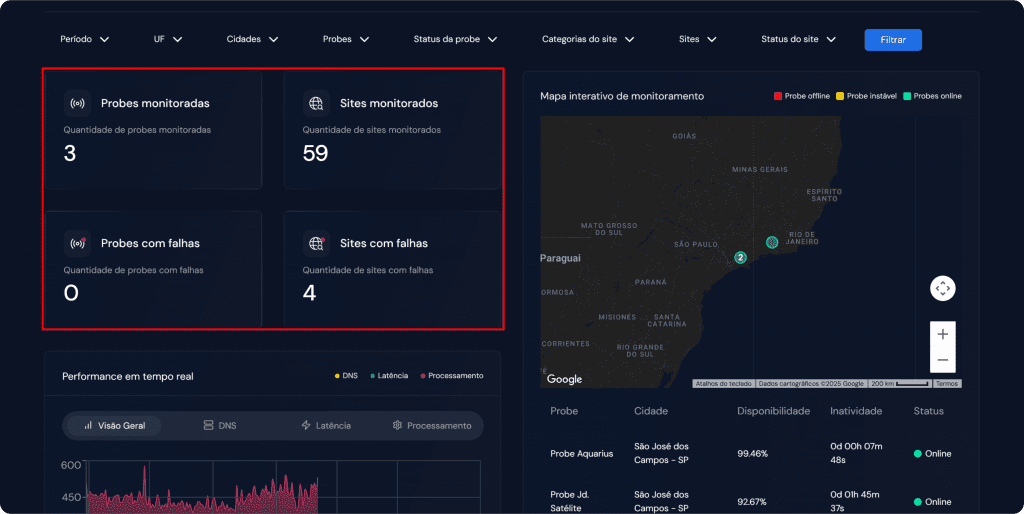
Na parte superior do Dashboard ao lado esquerdo, você verá cartões com métricas essenciais:
- Total de probes monitoradas
- Total de probes com falhas ativas
- Total de sites monitorados
- Total de sites com falhas ativas
Observação: Os cards de “Probes com falhas” e “Sites com falhas” são interativos. Ao clicar neles, você será redirecionado para as respectivas páginas (Probes ou Sites monitorados) já filtradas para exibir apenas os itens que estão com falha, facilitando a triagem imediata.
Mapa interativo de monitoramento #
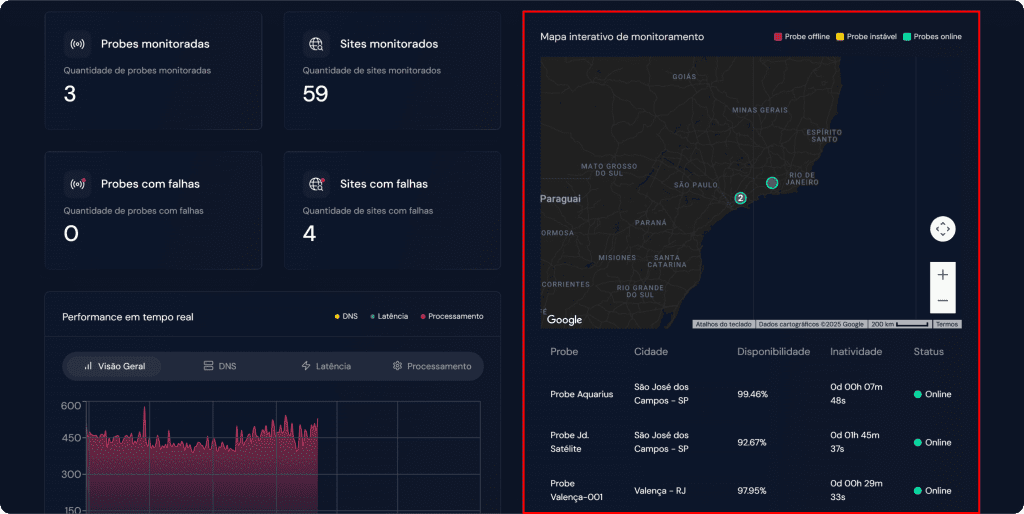
O mapa interativo de monitoramento exibe uma visualização geográfica do status da rede em cada cidade onde há sondas ativas. Ele permite identificar rapidamente regiões afetadas por falhas ou instabilidades.
Cada cidade é representada por um marcador com uma cor específica, de acordo com a condição da rede naquele local:
- Verde – Online: Todas as sondas da cidade estão ativas e enviando dados normalmente. Nenhum sinal de falha ou instabilidade foi detectado.
- Amarelo – Instável: As sondas estão ativas, mas os dados recebidos indicam instabilidade na conexão, como aumento de latência, quedas parciais de serviços, oscilações no tempo de resposta, entre outros.
- Vermelho – Offline: As sondas da cidade estão completamente inativas, geralmente desligadas ou sem conexão com a internet.
Gráfico de performance geral #
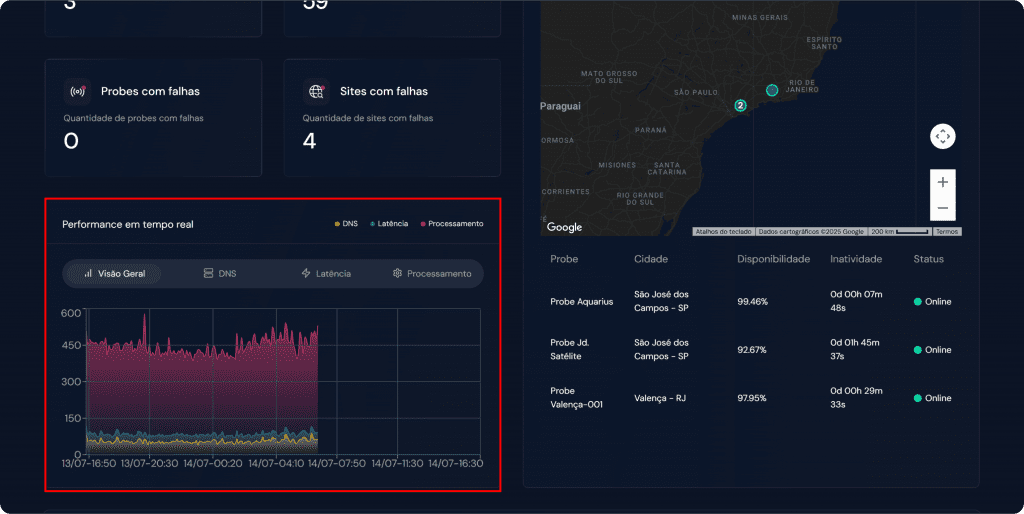
Este componente apresenta um gráfico de linhas que consolida a média de performance de todos os sites monitorados. Ele é dividido nas seguintes métricas:
- Média de tempo de DNS
- Média de latência
- Média de processamento
Ao analisar as variações ao longo do tempo, é possível identificar qual fator está mais impactando a experiência dos usuários. O gráfico é ideal para detectar tendências, identificar gargalos e acompanhar os efeitos de ações corretivas.
Para que serve
Esse gráfico ajuda você a:
- Identificar tendências de degradação ao longo do tempo
- Perceber qual métrica está impactando mais a experiência do usuário final
- Monitorar melhorias ou pioras após ações corretivas
Como interpretar
- Picos de tempo de DNS podem indicar lentidão na resolução de nomes de domínio, problemas com o provedor de DNS ou falhas no cache.
- Aumento de latência geralmente está ligado a instabilidades na rede, perda de pacotes ou rotas congestionadas.
- Elevação no tempo de processamento aponta para lentidão na resposta dos serviços monitorados, podendo envolver servidores de destino ou aplicações com falhas.
Tabela dos últimos incidentes registrados #
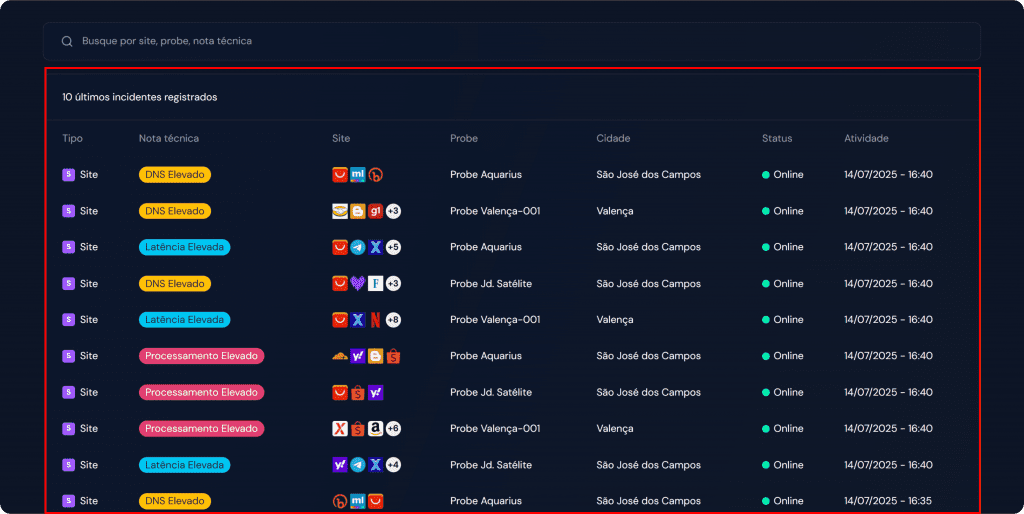
Essa tabela apresenta os 10 problemas mais recentes detectados pelo sistema de monitoramento, abrangendo tanto sondas quanto sites monitorados,
A tabela é voltada para facilitar a triagem rápida e a priorização de resposta técnica, especialmente em ambientes de operação.
Campos exibidos:
- Tipo do incidente: indica a origem do incidente
- Nota técnica: descrição resumida do incidente, com informações sobre a causa provável ou comportamento observado.
- Site: ícone do site que apresentou o problema.
- Probe: identificação da probe que registrou o incidente.
- Cidade: localização da probe, indicando onde o problema foi detectado geograficamente.
- Status: status da probe no momento do incidente
- Atividade: data e hora em que a sonda realizou a coleta de dados